一、眾安金融MLOps簡(jiǎn)介
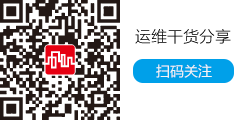
1、什么是MLOps
MLOps是將機(jī)器學(xué)習(xí)、數(shù)據(jù)工程和DevOps融合在一起,從而實(shí)現(xiàn)機(jī)器學(xué)習(xí)模型的高效迭代和持續(xù)穩(wěn)定地應(yīng)用于生產(chǎn)業(yè)務(wù)的一套方法架構(gòu)。所以它是一套實(shí)踐方法論,是一套架構(gòu)方案。
(2)協(xié)作團(tuán)隊(duì)
①數(shù)據(jù)產(chǎn)品團(tuán)隊(duì):定義業(yè)務(wù)目標(biāo),衡量業(yè)務(wù)價(jià)值。
②數(shù)據(jù)工程團(tuán)隊(duì):采集業(yè)務(wù)數(shù)據(jù),然后對(duì)數(shù)據(jù)進(jìn)行清洗轉(zhuǎn)換。
③數(shù)據(jù)科學(xué)家團(tuán)隊(duì):構(gòu)建ML解決方案,開(kāi)發(fā)相應(yīng)的特征模型。
④數(shù)據(jù)應(yīng)用團(tuán)隊(duì):模型應(yīng)用,對(duì)特征進(jìn)行持續(xù)的監(jiān)控。
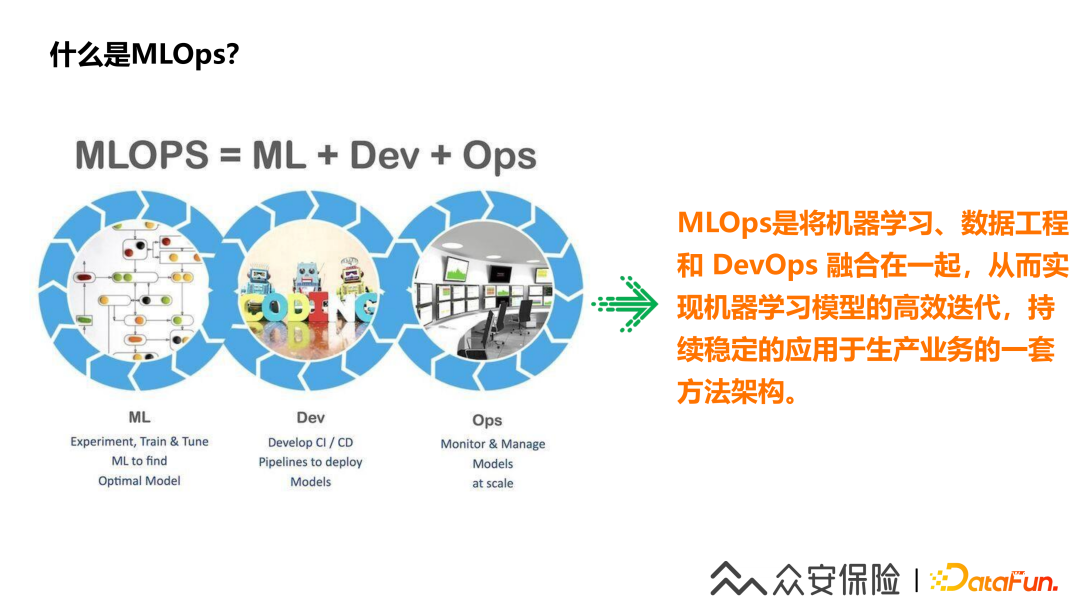
2、眾安金融MLOps流程說(shuō)明
(1)樣本準(zhǔn)備,產(chǎn)品業(yè)務(wù)團(tuán)隊(duì)定義業(yè)務(wù)范圍,確定建模的目標(biāo),選擇樣本人群準(zhǔn)備訓(xùn)練集。
(2)數(shù)據(jù)處理,需要對(duì)數(shù)據(jù)進(jìn)行缺失值、異常值、錯(cuò)誤值、數(shù)據(jù)格式的的清洗,使用連續(xù)變量、離散變量、時(shí)間序列等進(jìn)行數(shù)據(jù)轉(zhuǎn)換。
(3)特征開(kāi)發(fā),數(shù)據(jù)處理完成后就可以進(jìn)行特征衍生,金融特征主要通過(guò)審批邏輯衍生,行為總結(jié)量化,窮舉法,去量綱,分箱,WoE,降維,One-Hot編碼等進(jìn)行特征衍生,之后依據(jù)特征質(zhì)量,比如特征指標(biāo)(ks、iv、psi)或者預(yù)計(jì)逾期率等進(jìn)行特征篩選。
(4)模型開(kāi)發(fā),要進(jìn)行算法的選擇和模型的擬合。
(5)模型訓(xùn)練,使用測(cè)試數(shù)據(jù)集進(jìn)行模型算法的測(cè)試驗(yàn)證,進(jìn)行參數(shù)的調(diào)優(yōu)。
(6)模型應(yīng)用,模型開(kāi)發(fā)好之后就需要進(jìn)行線上化的一個(gè)部署。
(7)模型監(jiān)控,上線后需要持續(xù)的監(jiān)控和模型的迭代優(yōu)化。
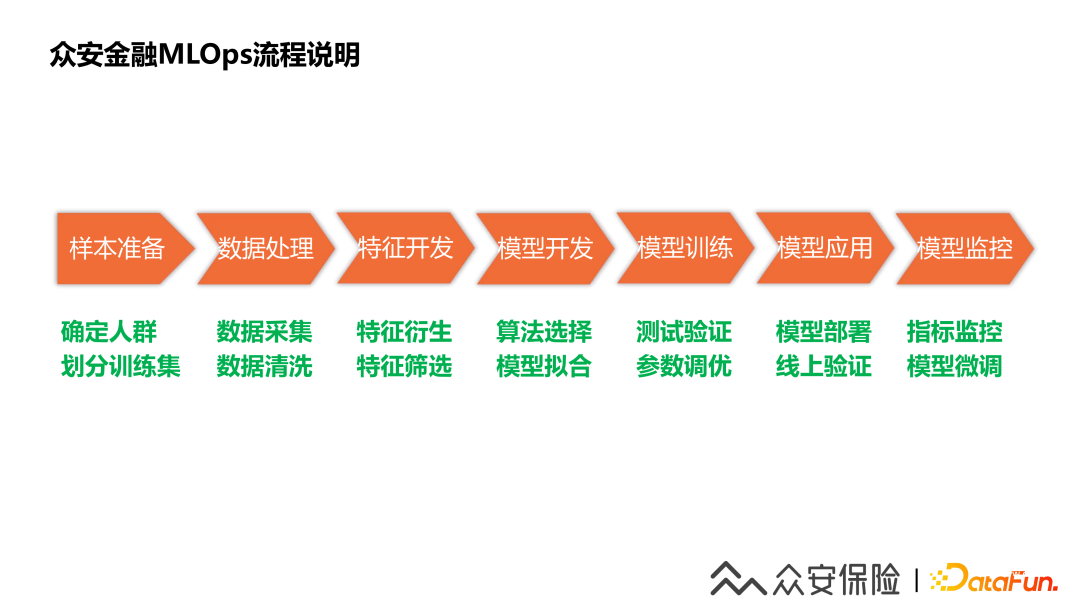
3、眾安金融為什么需要建設(shè)MLOps?
眾安金融,一方面為普惠人群提供公信征信支持,另一方面也為銀行等資金機(jī)構(gòu)來(lái)提供風(fēng)險(xiǎn)緩釋,助力普惠金融。眾安金融為無(wú)抵押的純線上消費(fèi)貸款平臺(tái)提供信用保證保險(xiǎn)服務(wù),也為其他金融機(jī)構(gòu)提供信用保證保險(xiǎn)服務(wù)。
眾安保險(xiǎn)作為保險(xiǎn)公司在其中承擔(dān)理賠的責(zé)任,所以就要求我們需要對(duì)風(fēng)險(xiǎn)進(jìn)行全面識(shí)別、準(zhǔn)確計(jì)量、嚴(yán)密監(jiān)控。我們搭建了以大數(shù)據(jù)為基礎(chǔ)、以風(fēng)控規(guī)則與模型為策略,以系統(tǒng)平臺(tái)為工具的大數(shù)據(jù)風(fēng)控體系。通過(guò)利用大數(shù)據(jù)與個(gè)人信用的關(guān)聯(lián)挖掘出大量的用戶風(fēng)險(xiǎn)特征和風(fēng)險(xiǎn)模型,從而提升風(fēng)控的預(yù)測(cè)能力。
隨著風(fēng)控策略的精細(xì)化,模型應(yīng)用的規(guī)模化,特征使用的實(shí)時(shí)化,對(duì)我們的特征開(kāi)發(fā)和模型應(yīng)用提出了更快速更實(shí)時(shí)的要求,所以我們就開(kāi)始嘗試進(jìn)行特征平臺(tái)體系化的實(shí)踐。
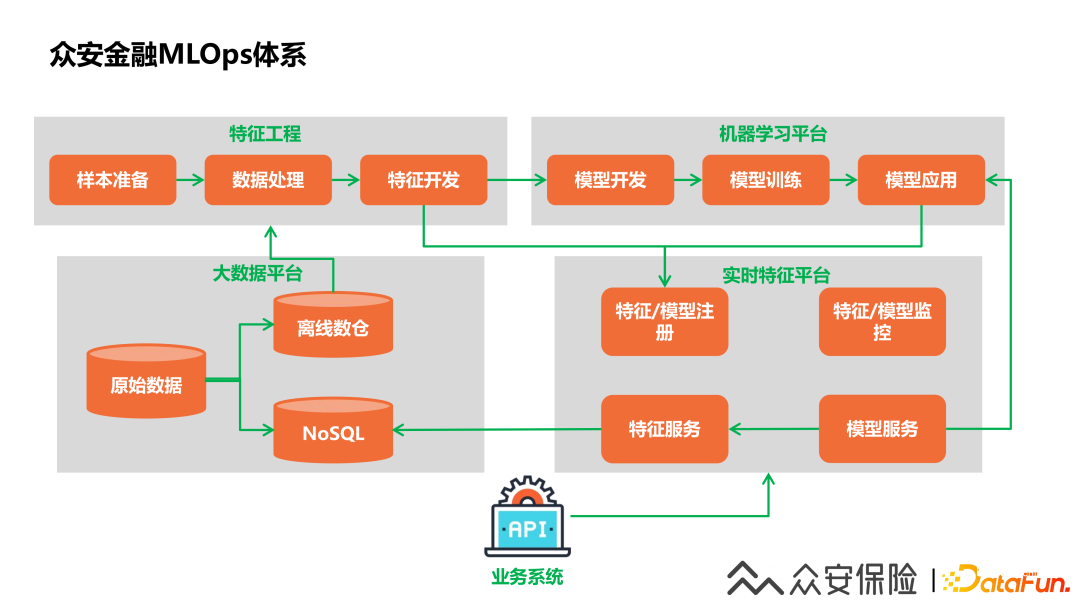
4、眾安金融MLOps體系
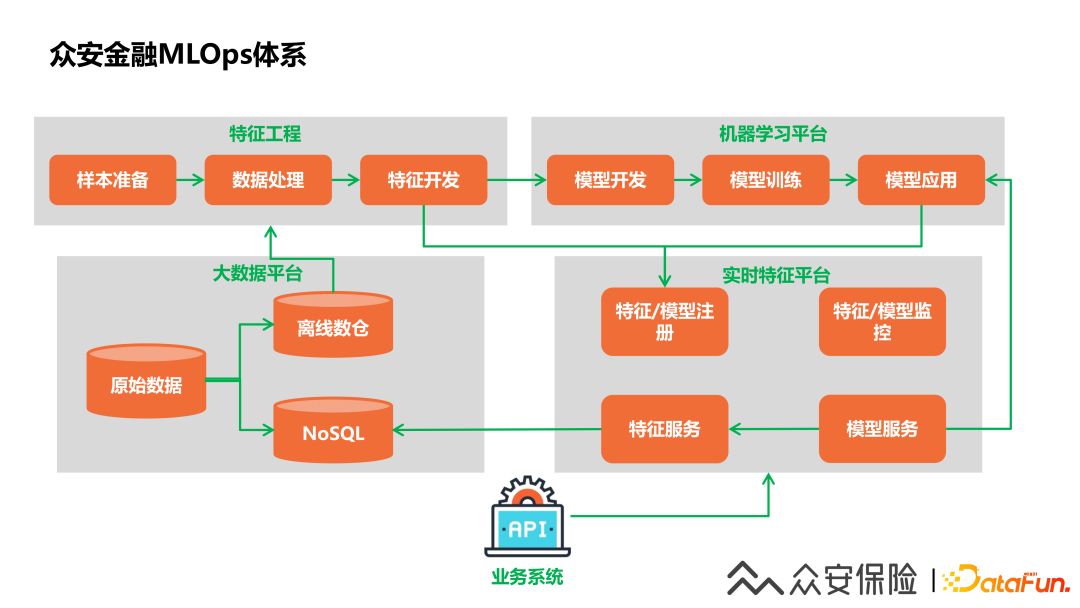
(1)大數(shù)據(jù)平臺(tái):數(shù)據(jù)開(kāi)發(fā)工程師使用大數(shù)據(jù)平臺(tái)的能力采集到相關(guān)的業(yè)務(wù)數(shù)據(jù),構(gòu)建基于主題域的離線數(shù)據(jù)體系,同時(shí)把相應(yīng)的數(shù)據(jù)回流同步到在線NoSQL存儲(chǔ)引擎,提供給實(shí)時(shí)特征平臺(tái)使用。
(2)特征工程:數(shù)據(jù)科學(xué)家在大數(shù)據(jù)平臺(tái)進(jìn)行特征工程的建設(shè),使用離線數(shù)倉(cāng)進(jìn)行特征的挖掘和特征的選擇。
(3)機(jī)器學(xué)習(xí)平臺(tái):數(shù)據(jù)科學(xué)家借助機(jī)器學(xué)習(xí)平臺(tái)可以進(jìn)行一站式的模型開(kāi)發(fā)和應(yīng)用。
(4)實(shí)時(shí)特征平臺(tái):開(kāi)發(fā)好的特征和模型需要在實(shí)時(shí)特征平臺(tái)進(jìn)行注冊(cè),在實(shí)時(shí)特征平臺(tái)配置好相關(guān)的信息后,就可以通過(guò)實(shí)時(shí)特征平臺(tái)的數(shù)據(jù)服務(wù)能力,提供上游業(yè)務(wù)的特征查詢和模型應(yīng)用的能力。
二、實(shí)時(shí)特征平臺(tái)架構(gòu)設(shè)計(jì)
1、眾安金融特征應(yīng)用場(chǎng)景
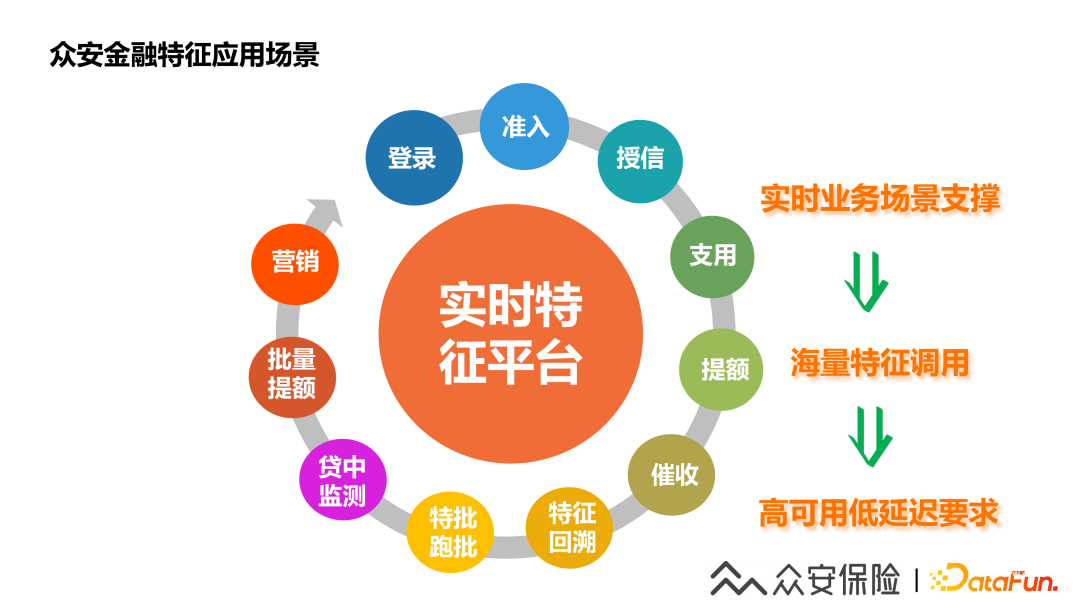
眾安金融實(shí)時(shí)特征平臺(tái)服務(wù)于金融業(yè)務(wù)全流程,包含金融線上的核心業(yè)務(wù)場(chǎng)景如登錄,準(zhǔn)入,授信,支用,提額等實(shí)時(shí)前臺(tái)場(chǎng)景,后臺(tái)業(yè)務(wù)場(chǎng)景更多是批量的特征調(diào)用場(chǎng)景,此外還有催收也有對(duì)于特征和模型的使用,一開(kāi)始特征平臺(tái)的初衷是為風(fēng)控體系服務(wù),隨著業(yè)務(wù)的發(fā)展,模型也逐漸使用到了用戶營(yíng)銷場(chǎng)景和一些資源位的用戶推薦服務(wù)中。這里值得注意的是,對(duì)風(fēng)控業(yè)務(wù)了解的同學(xué)就會(huì)知道,一次風(fēng)控策略會(huì)有多個(gè)風(fēng)控規(guī)則,每個(gè)風(fēng)控規(guī)則會(huì)查詢多個(gè)特征數(shù)據(jù),所以一次業(yè)務(wù)交易對(duì)于實(shí)時(shí)特征平臺(tái)來(lái)說(shuō)可能就會(huì)放大到幾百倍的調(diào)用。
2、眾安金融特征數(shù)據(jù)分類

(1)交易行為數(shù)據(jù):包含授信,借款申請(qǐng)、還款的數(shù)據(jù),調(diào)額和逾期數(shù)據(jù)等業(yè)務(wù)數(shù)據(jù)。
(2)三方征信數(shù)據(jù):需要對(duì)接三方征信機(jī)構(gòu)的接口。
(3)設(shè)備抓取數(shù)據(jù):在用戶授權(quán)允許的情況下獲取設(shè)備相關(guān)信息。
(4)用戶行為數(shù)據(jù):通過(guò)用戶行為埋點(diǎn)獲取。
3、實(shí)時(shí)特征平臺(tái)核心能力

面對(duì)眾多的特征數(shù)據(jù)源,這就要求我們實(shí)時(shí)特征平臺(tái)具備豐富的數(shù)據(jù)接入能力,實(shí)時(shí)的數(shù)據(jù)處理能力,對(duì)于大量的特征需求也要求特征平臺(tái)具備高效的特征加工配置化能力,實(shí)時(shí)的業(yè)務(wù)調(diào)用要求平臺(tái)有快速的系統(tǒng)響應(yīng)能力,我們也是圍繞這些核心能力的要求進(jìn)行特征平臺(tái)的技術(shù)選型和架構(gòu)設(shè)計(jì)。經(jīng)過(guò)了技術(shù)迭代選型,我們采用了Flink作為實(shí)時(shí)計(jì)算引擎,使用阿里云的TableStore作為高性能的存儲(chǔ)引擎,然后通過(guò)微服務(wù)化的架構(gòu)實(shí)現(xiàn)了系統(tǒng)的服務(wù)化和平臺(tái)化。
4、實(shí)時(shí)特征平臺(tái)的業(yè)務(wù)架構(gòu)
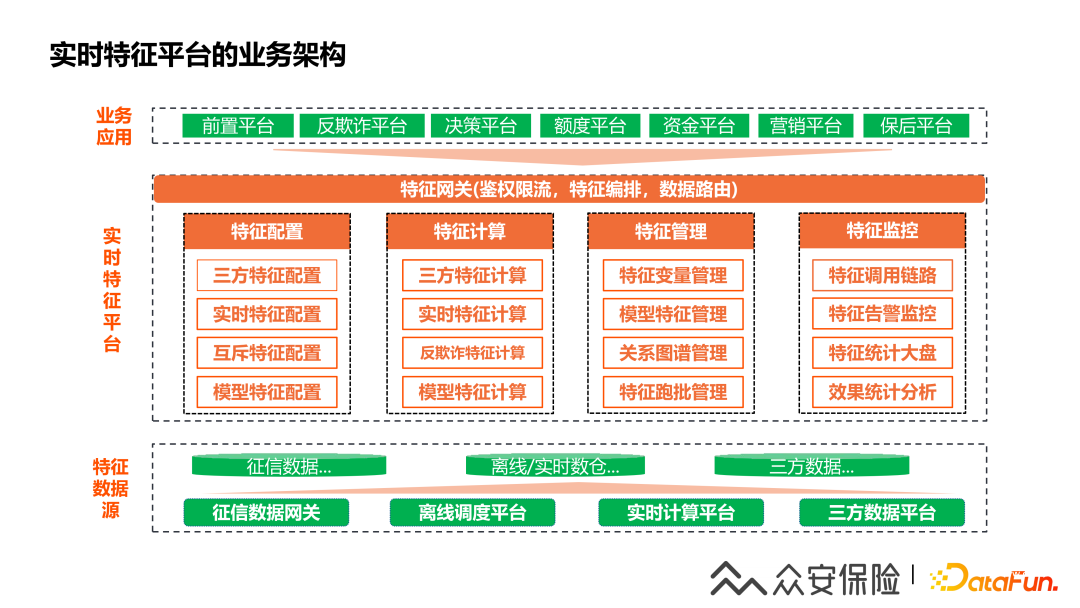
這張圖是我們的實(shí)時(shí)特征平臺(tái)的業(yè)務(wù)架構(gòu)圖,可以看到圖的底層是特征數(shù)據(jù)源層,中間層是實(shí)時(shí)特征平臺(tái)的核心功能層,上層是整個(gè)特征平臺(tái)體系的業(yè)務(wù)應(yīng)用層,特征平臺(tái)主要有四個(gè)數(shù)據(jù)源:
(1)征信數(shù)據(jù)網(wǎng)關(guān):提供人行征信等征信機(jī)構(gòu)的用戶信用數(shù)據(jù),需要通過(guò)實(shí)時(shí)的接口對(duì)接來(lái)查詢征信數(shù)據(jù)。
(2)三方數(shù)據(jù)平臺(tái):提供外部數(shù)據(jù)服務(wù)商的數(shù)據(jù),通過(guò)調(diào)用三方數(shù)據(jù)接口服務(wù)完成實(shí)時(shí)數(shù)據(jù)對(duì)接。
(3)實(shí)時(shí)計(jì)算平臺(tái):實(shí)時(shí)接入業(yè)務(wù)系統(tǒng)的交易數(shù)據(jù),用戶行為數(shù)據(jù)和抓取設(shè)備數(shù)據(jù),通過(guò)實(shí)時(shí)計(jì)算后回流到NoSQL在線存儲(chǔ)引擎。
(4)離線調(diào)用平臺(tái):離線數(shù)據(jù)在阿里云的MaxComputer計(jì)算后同步到NoSQL存儲(chǔ),實(shí)現(xiàn)歷史數(shù)據(jù)的回流,從而支撐用戶全業(yè)務(wù)時(shí)間序列的特征計(jì)算,此外一些非實(shí)時(shí)指標(biāo)也需要在離線數(shù)倉(cāng)加工完成后再回流到NoSQL存儲(chǔ)引擎。
實(shí)時(shí)特征平臺(tái)的核心功能:
?(1)特征網(wǎng)關(guān):特征網(wǎng)關(guān)是特征查詢的出入口,具備鑒權(quán)限流,特征數(shù)據(jù)編排等功能。
(2)特征配置:為了支持特征的快速上線,特征平臺(tái)實(shí)現(xiàn)了特征的配置化能力,包含三方數(shù)據(jù)特征配置,實(shí)時(shí)業(yè)務(wù)特征配置,互斥規(guī)則特征配置,模型特征配置能力。
(3)特征計(jì)算:特征計(jì)算是通過(guò)微服務(wù)化的子系統(tǒng)來(lái)實(shí)現(xiàn)的,主要有三方特征計(jì)算,實(shí)時(shí)特征計(jì)算,反欺詐特征計(jì)算,模型特征計(jì)算。
(4)特征管理:特征管理后臺(tái)提供了特征變量生命周期管理能力,模型的元數(shù)據(jù)管理,還有特征跑批的任務(wù)管理。
(5)特征監(jiān)控:具備特征調(diào)用全鏈路查詢能力,對(duì)于特征計(jì)算失敗,特征值異常值,模型PSI值波動(dòng)進(jìn)行實(shí)時(shí)告警,此外也提供了特征使用情況等統(tǒng)計(jì)分析大盤報(bào)表。?
5、三方數(shù)據(jù)實(shí)時(shí)接入方案
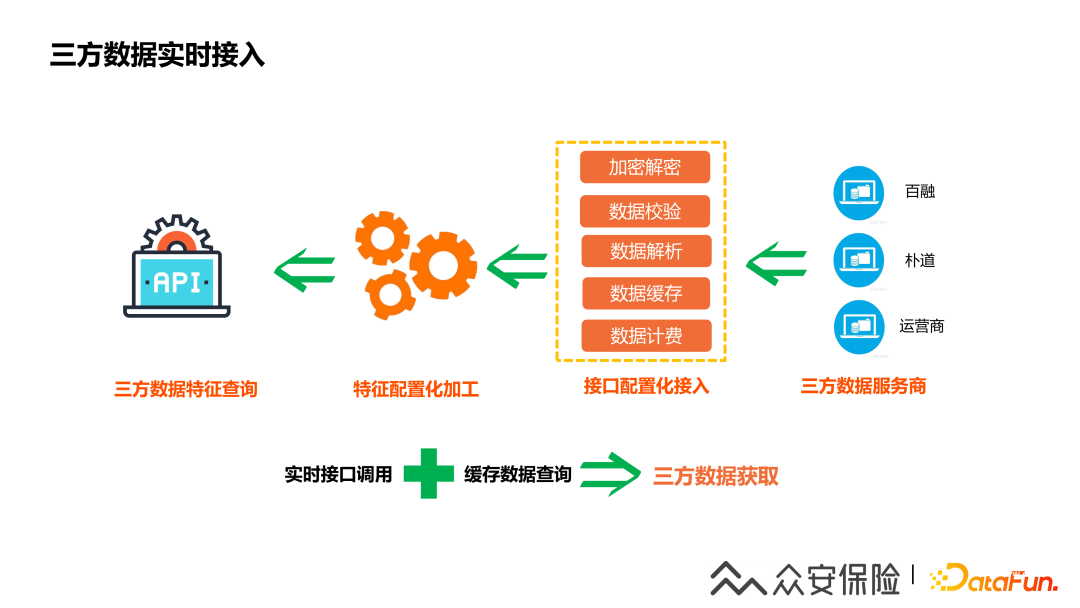
(1)查詢方式:調(diào)用三方征信機(jī)構(gòu)的實(shí)時(shí)接口獲取報(bào)文數(shù)據(jù)然后進(jìn)行數(shù)據(jù)處理獲取特征結(jié)果,出于降本考慮,我們還會(huì)實(shí)現(xiàn)一套緩存機(jī)制,對(duì)于離線場(chǎng)景減少調(diào)用三方的次數(shù)。
(2)創(chuàng)新點(diǎn):三方數(shù)據(jù)接入引擎可以通過(guò)純配置化的方式接入三方的數(shù)據(jù)接口,通過(guò)特征加工引擎實(shí)現(xiàn)自動(dòng)化的特征生成,通過(guò)可視化界面提供配置化的能力,最后通過(guò)接口提供給上游使用三方特征計(jì)算服務(wù)。
(3)解決的難點(diǎn):三方數(shù)據(jù)與配置化接入的難點(diǎn)是數(shù)據(jù)服務(wù)商的加密方式、簽名機(jī)制多樣性、復(fù)雜性,三方數(shù)據(jù)接入引擎通過(guò)內(nèi)置一套加解密函數(shù)和支持自定義函數(shù)的能力,結(jié)合函數(shù)的鏈?zhǔn)浇M合方式,完成了各種復(fù)雜的三方數(shù)據(jù)加解密的配置化的實(shí)現(xiàn)。
6、業(yè)務(wù)數(shù)據(jù)實(shí)時(shí)接入
實(shí)時(shí)業(yè)務(wù)數(shù)據(jù)的接入由兩部分組成,首先是通過(guò)Flink實(shí)時(shí)監(jiān)聽(tīng)業(yè)務(wù)數(shù)據(jù)庫(kù)的Binlog數(shù)據(jù)寫入到實(shí)時(shí)數(shù)倉(cāng),還有一部分使用Spark完成歷史數(shù)據(jù)的回補(bǔ),結(jié)合離線數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)就可以支持基于全量時(shí)序數(shù)據(jù)的特征加工能力,為了支持高性能的實(shí)時(shí)特征查詢,實(shí)時(shí)數(shù)據(jù)和離線數(shù)據(jù)都會(huì)回流到NoSQL存儲(chǔ)引擎。對(duì)于不同的數(shù)據(jù),我們也會(huì)考慮不同的存儲(chǔ)引擎,業(yè)務(wù)交易數(shù)據(jù)主要是用TableStore作為存儲(chǔ)引擎,用戶行為特征數(shù)據(jù)使用Redis為主,用戶關(guān)系圖譜數(shù)據(jù)用圖數(shù)據(jù)庫(kù)進(jìn)行存儲(chǔ),從整個(gè)流程來(lái)看,現(xiàn)在的數(shù)據(jù)體系是采用成熟的Lambda架構(gòu)。
7、實(shí)時(shí)特征平臺(tái)的系統(tǒng)架構(gòu)
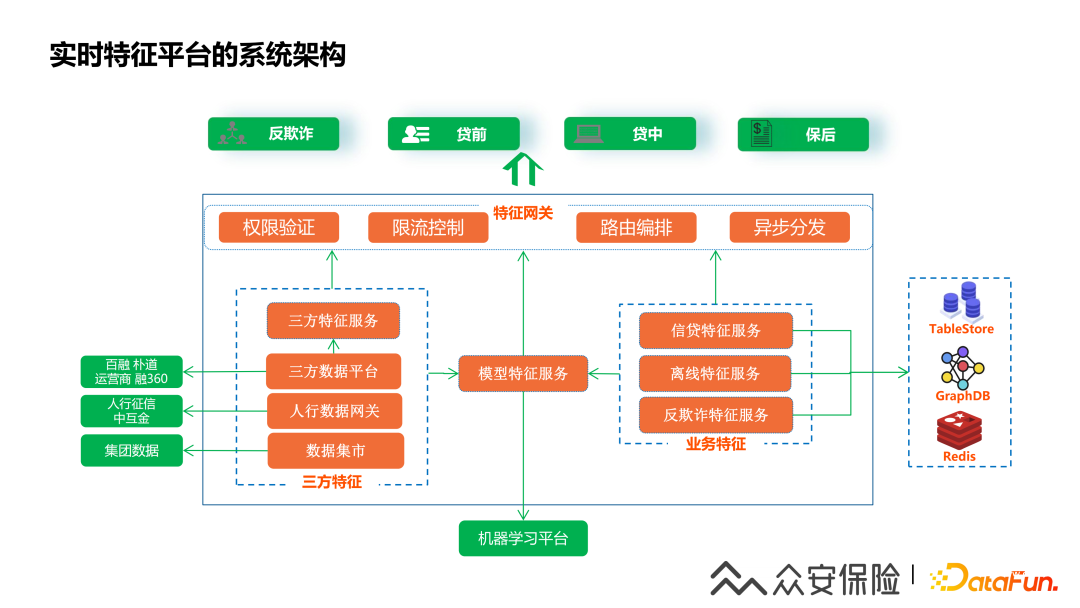
?我們實(shí)時(shí)特征平臺(tái)的架構(gòu)基本如上圖,上游業(yè)務(wù)經(jīng)過(guò)特征網(wǎng)關(guān)進(jìn)行特征的查詢,特征網(wǎng)關(guān)會(huì)進(jìn)行特征查詢權(quán)限的驗(yàn)證,限流控制和特征查詢?nèi)蝿?wù)異步分發(fā),特征網(wǎng)關(guān)首先根據(jù)特征元數(shù)據(jù)信息路由到不同的特征數(shù)據(jù)源,從特征數(shù)據(jù)源查詢到原始數(shù)據(jù)之后會(huì)再路由到不同的特征計(jì)算服務(wù)進(jìn)行特征的加工。三方特征是從三方數(shù)據(jù)平臺(tái)和征信網(wǎng)關(guān)查詢到的原始報(bào)文數(shù)據(jù)之后加工成為對(duì)應(yīng)的特征;業(yè)務(wù)特征計(jì)算用于加工內(nèi)部業(yè)務(wù)系統(tǒng)的實(shí)時(shí)特征。
信貸特征是通過(guò)實(shí)時(shí)業(yè)務(wù)數(shù)據(jù)同步后進(jìn)行特征加工計(jì)算,離線特征服務(wù)是在離線數(shù)倉(cāng)MaxComputer完成的特征加工計(jì)算。反欺詐特征計(jì)算用于對(duì)用戶登錄設(shè)備信息,用戶行為數(shù)據(jù)和用戶關(guān)系圖譜等相關(guān)特征的加工。
在基礎(chǔ)的三方特征,業(yè)務(wù)特征計(jì)算完成后,就可以直接提供給上游業(yè)務(wù)使用,此外模型服務(wù)也會(huì)依賴這些基礎(chǔ)特征,模型特征計(jì)算是借助機(jī)器學(xué)習(xí)平臺(tái)的能力來(lái)實(shí)現(xiàn)的,我們的機(jī)器學(xué)習(xí)平臺(tái)提供了模型的訓(xùn)練,測(cè)試,發(fā)布等一體化功能,特征平臺(tái)集成了機(jī)器學(xué)習(xí)平臺(tái)的能力從而實(shí)現(xiàn)了模型特征的自動(dòng)化和配置化。?
三、實(shí)時(shí)業(yè)務(wù)特征計(jì)算詳解
1、特征實(shí)時(shí)計(jì)算方案選型
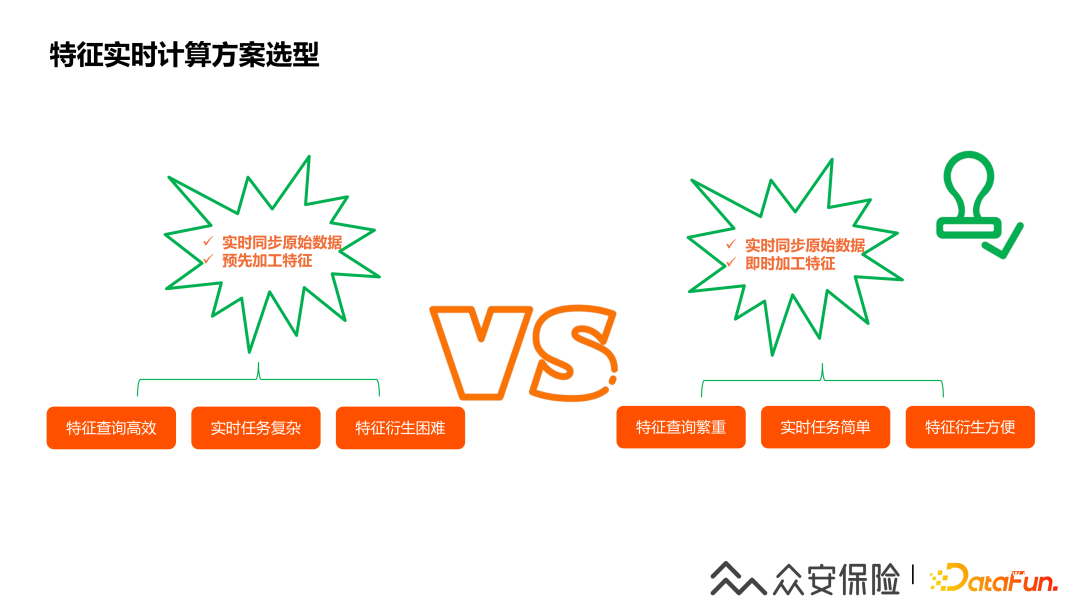
我覺(jué)得實(shí)時(shí)特征計(jì)算方案有兩種,第一種實(shí)時(shí)同步原始業(yè)務(wù)數(shù)據(jù),然后在實(shí)時(shí)計(jì)算任務(wù)同時(shí)實(shí)現(xiàn)特征的加工,這是傳統(tǒng)的ETL模式,這種方式的優(yōu)點(diǎn)是特征查詢非常高效,查詢性能好,但是實(shí)時(shí)任務(wù)計(jì)算復(fù)雜,需要大量實(shí)時(shí)計(jì)算資源,需要特征衍生的話也是比較困難;另外一個(gè)方式是實(shí)時(shí)同步原始業(yè)務(wù)明細(xì)數(shù)據(jù),但是特征加工是即時(shí)進(jìn)行,也就是說(shuō)特征查詢時(shí)再進(jìn)行特征的計(jì)算,這樣方式特征查詢計(jì)算繁重,需要高速特征查詢引擎支持,但是實(shí)時(shí)任務(wù)比較簡(jiǎn)單,特征衍生也比較方便,這個(gè)較新的ELT模式。出于我們業(yè)務(wù)對(duì)于特征頻繁衍生的要求和節(jié)省實(shí)時(shí)計(jì)算資源的考慮,我們選擇了第ELT的即時(shí)加工特征的方案。
2、實(shí)時(shí)業(yè)務(wù)特征數(shù)據(jù)流
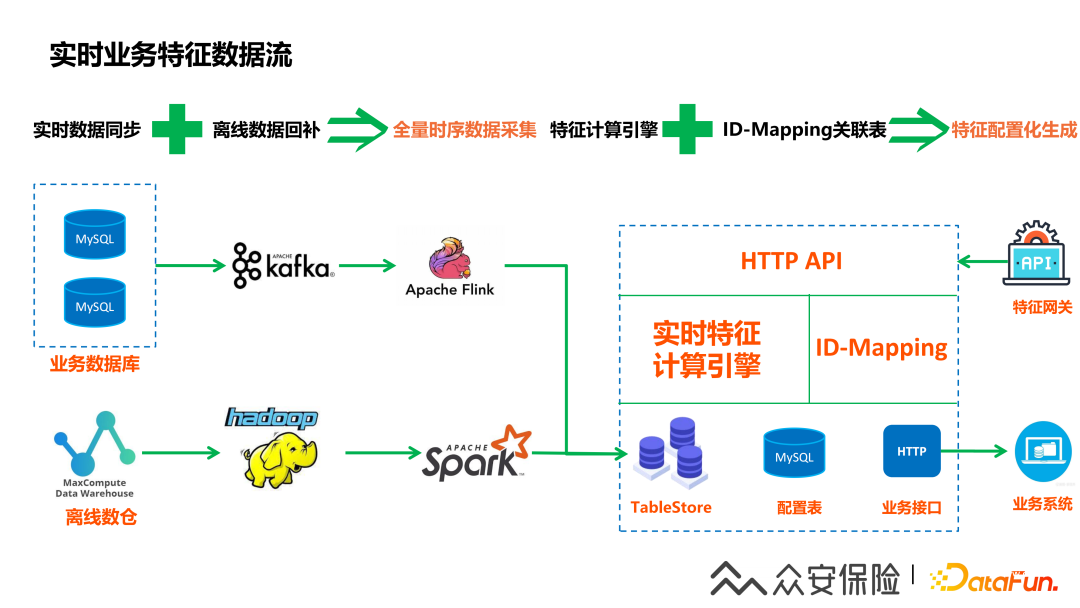
除了通過(guò)Flink實(shí)時(shí)采集的數(shù)據(jù)外,還有部分?jǐn)?shù)據(jù)需要調(diào)用業(yè)務(wù)系統(tǒng)的接口來(lái)獲取,這種數(shù)據(jù)也可以注冊(cè)為特征數(shù)據(jù)引擎的元數(shù)據(jù),和存儲(chǔ)在TableStore里的數(shù)據(jù)一樣進(jìn)行配置化使用。我們采用了阿里云的TableStore這個(gè)比較穩(wěn)定的高速查詢引擎來(lái)支持實(shí)時(shí)特征查詢,但是其實(shí)云產(chǎn)品的成本也需要考慮的,所以大家也需要根據(jù)本身的現(xiàn)狀選擇合適的方案。
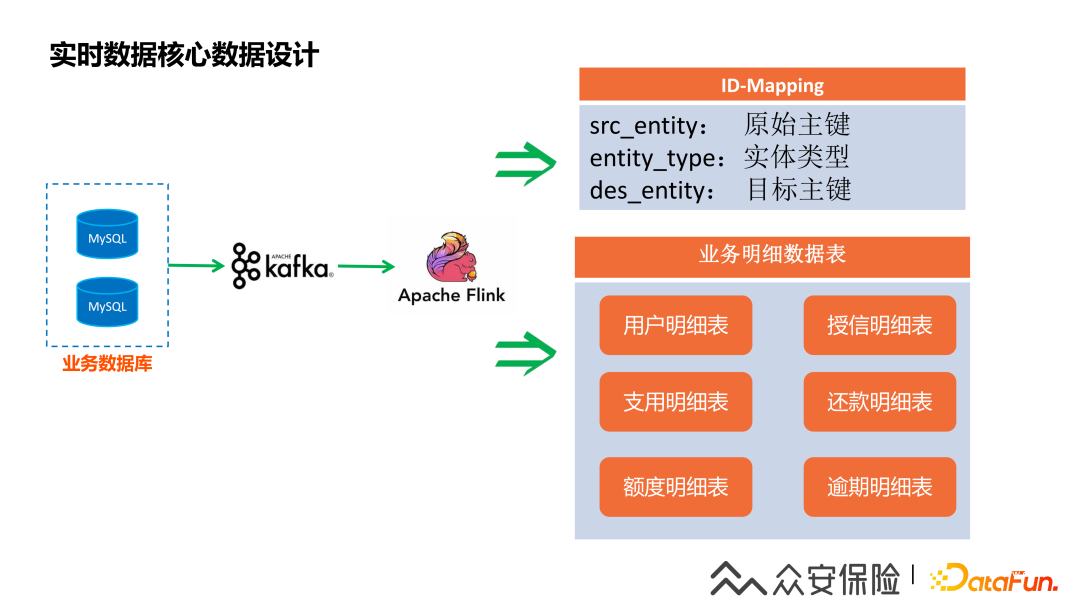
3、實(shí)時(shí)數(shù)據(jù)核心數(shù)據(jù)設(shè)計(jì)
由于我們存在多條產(chǎn)品線,每個(gè)產(chǎn)品線的用戶主鍵也都不同,而金融業(yè)務(wù)場(chǎng)景主要是以用戶身份證,用戶手機(jī)號(hào)等維度進(jìn)行特征的查詢,因此我們抽象了一套用戶實(shí)體關(guān)系的ID-Mapping表,實(shí)現(xiàn)了身份證,手機(jī)號(hào)等維度到用戶主鍵的關(guān)聯(lián)關(guān)系,特征查詢時(shí)首先會(huì)根據(jù)特征入?yún)⒉樵僆D-Mapping表獲取用戶ID,然后再根據(jù)用戶ID查詢用戶業(yè)務(wù)明細(xì)數(shù)據(jù),主要的業(yè)務(wù)明細(xì)數(shù)據(jù)包含用戶授信數(shù)據(jù),支用明細(xì),還款明細(xì),額度明細(xì),逾期明細(xì)的用戶業(yè)務(wù)數(shù)據(jù)。這里我們踩過(guò)的一個(gè)坑是主副表同時(shí)更新的場(chǎng)景,我們把主副表存儲(chǔ)為一份特征數(shù)據(jù),我們主要是使用columnfamily的方式存儲(chǔ)數(shù)據(jù),所以在高并發(fā)的場(chǎng)景,可能會(huì)造成主副表同時(shí)更新帶來(lái)的不一致的情況,我們現(xiàn)在是通過(guò)一個(gè)窗口任務(wù)實(shí)現(xiàn)數(shù)據(jù)的補(bǔ)償。下圖是主要的業(yè)務(wù)數(shù)據(jù)圖:
4、實(shí)時(shí)特征計(jì)算引擎
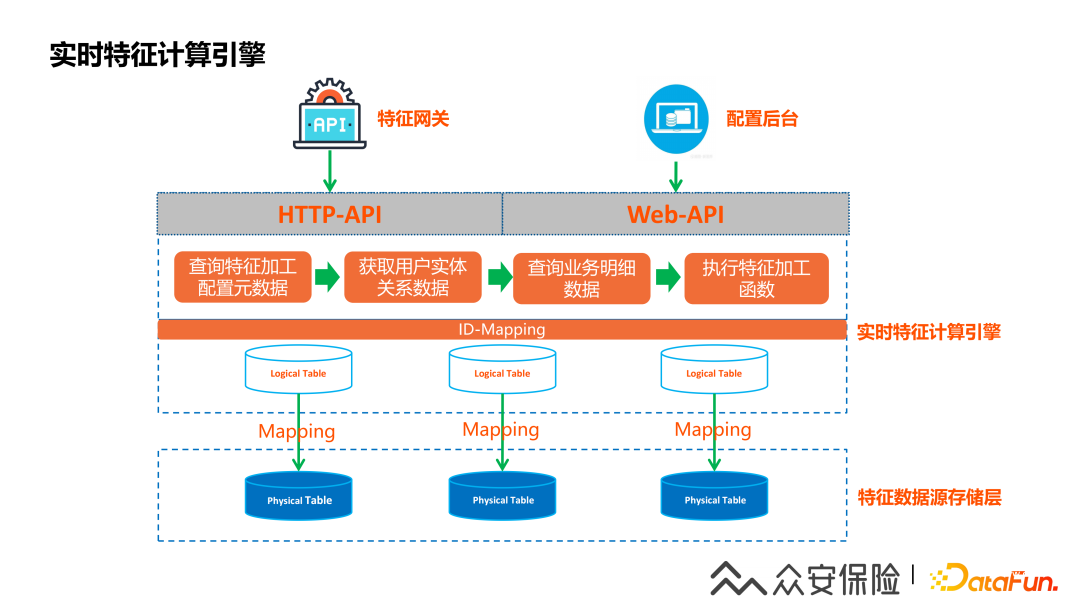
早期的特征加工是通過(guò)開(kāi)發(fā)人員寫代碼來(lái)實(shí)現(xiàn)的,隨著特征需求增加,為了支撐特征的快速上線,我們借助表達(dá)式語(yǔ)言和Groovy實(shí)現(xiàn)了一套基于特征計(jì)算函數(shù)的特征配置化能力,結(jié)合ID-Mapping實(shí)現(xiàn)了一個(gè)特征計(jì)算引擎,計(jì)算過(guò)程可以分為如下幾步:
(1)創(chuàng)建實(shí)時(shí)Flink任務(wù)把用戶關(guān)系數(shù)據(jù)同步到ID-Mapping表,從而支持用戶多維數(shù)據(jù)查詢。
(2)創(chuàng)建實(shí)時(shí)Flink任務(wù)把用戶業(yè)務(wù)數(shù)據(jù)回流到阿里云的TableStore,實(shí)現(xiàn)業(yè)務(wù)明細(xì)數(shù)據(jù)的實(shí)時(shí)同步。
(3)在特征平臺(tái)的實(shí)時(shí)特征配置頁(yè)面把上一步同步到TableStore的用戶業(yè)務(wù)數(shù)據(jù)表注冊(cè)為特征計(jì)算引擎邏輯數(shù)據(jù)。
(4)接下來(lái)在特征計(jì)算配置頁(yè)面選擇相關(guān)的特征元數(shù)據(jù),填寫特征基礎(chǔ)信息,特征加工的函數(shù),通過(guò)測(cè)試和上線等過(guò)程后這個(gè)特征就可以提供在線使用。
(5)特征查詢時(shí)首先會(huì)根據(jù)特征查詢?nèi)雲(yún)⒉樵僆D-Mapping表獲取用戶ID,然后根據(jù)用戶ID查詢TableStore里面的用戶明細(xì)業(yè)務(wù)數(shù)據(jù),特征計(jì)算引擎會(huì)把根據(jù)配置的特征計(jì)算表達(dá)式進(jìn)行特征數(shù)據(jù)查詢,計(jì)算出來(lái)的數(shù)據(jù)結(jié)果就是特征值,就和第四步提到的,會(huì)把特征組下面的所有特征都計(jì)算出來(lái)。
四、反欺詐場(chǎng)景的特征應(yīng)用
1、反欺詐特征分類

隨著金融欺詐風(fēng)險(xiǎn)不斷擴(kuò)大,反欺詐形勢(shì)也越來(lái)越嚴(yán)峻,特征平臺(tái)也不可避免的需要支持反欺詐特征的查詢需求,總結(jié)下了我們的反欺詐特征分類如下:
(1)用戶行為特征:主要是基于埋點(diǎn)的用戶行為數(shù)據(jù)進(jìn)行特征的衍生。比如用戶啟動(dòng)的APP的次數(shù)、頁(yè)面訪問(wèn)的時(shí)長(zhǎng),還有點(diǎn)擊的次數(shù)和在某個(gè)輸入框輸入的次數(shù)等。
(2)位置識(shí)別特征:主要是基于用戶的實(shí)時(shí)地理位置信息,加上GeoHash算法能力,實(shí)現(xiàn)位置特征的數(shù)據(jù)計(jì)算。
(3)設(shè)備關(guān)聯(lián)特征:主要是通過(guò)用戶關(guān)系圖譜來(lái)實(shí)現(xiàn),通過(guò)獲取同一個(gè)設(shè)備下關(guān)聯(lián)到用戶的情況,可以快速地定位羊毛黨等欺詐行為。
(4)用戶圖譜關(guān)系特征:通過(guò)實(shí)時(shí)的獲取用戶在登錄、注冊(cè)、授信、資用等關(guān)鍵業(yè)務(wù)場(chǎng)景的設(shè)備信息,結(jié)合用戶三要素和他的一些聯(lián)系人信息,構(gòu)建圖譜關(guān)系,然后通過(guò)查詢用戶的鄰邊關(guān)系、用戶關(guān)聯(lián)的用戶是否有黑灰名單的情況,進(jìn)行風(fēng)險(xiǎn)識(shí)別。
(5)用戶社群特征:通過(guò)判斷社群的大小、社群里用戶行為的表現(xiàn),提煉社群規(guī)則特征。
2、實(shí)時(shí)反欺詐特征數(shù)據(jù)流

反欺詐特征計(jì)算的數(shù)據(jù)流程和實(shí)時(shí)特征計(jì)算數(shù)據(jù)流程類似,除了數(shù)據(jù)源來(lái)源于實(shí)時(shí)業(yè)務(wù)數(shù)據(jù)外,反欺詐場(chǎng)景更關(guān)注是埋點(diǎn)的用戶行為數(shù)據(jù),抓取的用戶設(shè)備數(shù)據(jù),提取的用戶關(guān)聯(lián)關(guān)系數(shù)據(jù),用戶行為的數(shù)據(jù)會(huì)通過(guò)埋點(diǎn)平臺(tái)(XFlow)上報(bào)到Kafka,這些數(shù)據(jù)也會(huì)是使用Flink進(jìn)行實(shí)時(shí)加工計(jì)算,不過(guò)和實(shí)時(shí)業(yè)務(wù)特征處理的區(qū)別是反欺詐特征是在實(shí)時(shí)數(shù)倉(cāng)里面直接計(jì)算好之后存儲(chǔ)到Redis,圖數(shù)據(jù)庫(kù)等存儲(chǔ)里面,這個(gè)是為了滿足反欺詐特征查詢的高性能要求,此外反欺詐場(chǎng)景也更關(guān)注實(shí)時(shí)的數(shù)據(jù)變化。從上圖可以了解到,反欺詐特征通過(guò)HTTPAPI的接口方式為特征網(wǎng)關(guān)提供特征計(jì)算服務(wù)。
3、關(guān)系圖譜架構(gòu)圖
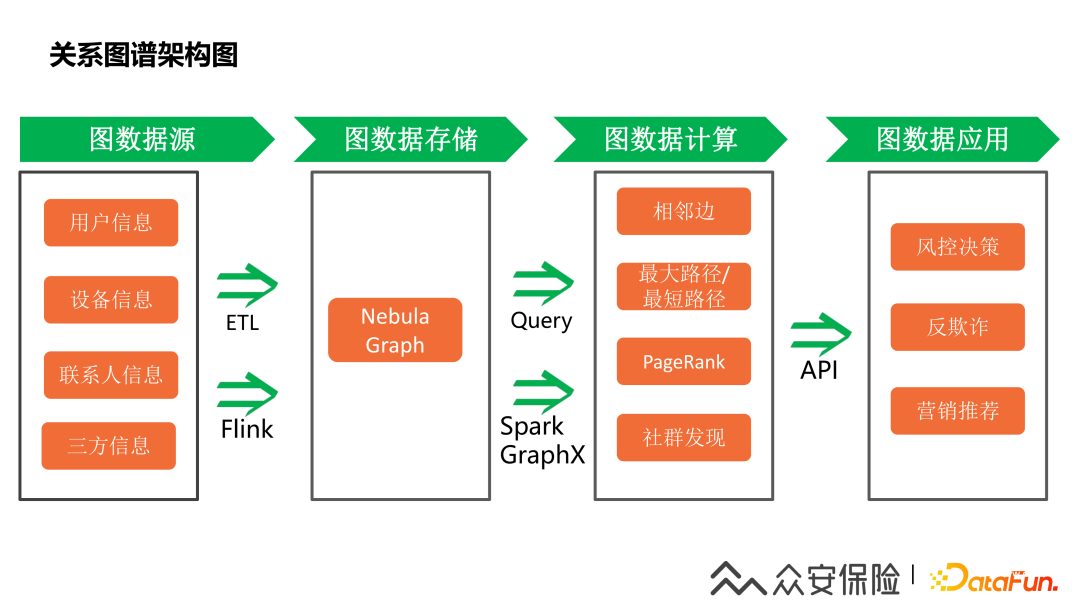
用戶關(guān)系圖譜的建設(shè)情況,整體設(shè)計(jì)思路如下:
?(1)首先是對(duì)于圖的數(shù)據(jù)源的選擇,要想構(gòu)建比較有價(jià)值的用戶關(guān)系圖譜,一定要找到準(zhǔn)確的數(shù)據(jù)進(jìn)行圖建模。關(guān)系圖譜的數(shù)據(jù)源主要來(lái)自用戶數(shù)據(jù),比如手機(jī)號(hào)、身份證、設(shè)備信息、用戶三要素,聯(lián)系人等相關(guān)數(shù)據(jù)
(2)第二就是圖數(shù)據(jù)存儲(chǔ)引擎選型,需要關(guān)注的是引擎的穩(wěn)定性,數(shù)據(jù)的實(shí)時(shí)性,集成的方便性,查詢的高性能,存儲(chǔ)引擎的選擇非常重要,現(xiàn)在市面上有不少圖數(shù)據(jù)庫(kù)的技術(shù),選型的過(guò)程中其實(shí)也碰到過(guò)不少的坑,一開(kāi)始我們選擇的orientdb,在大數(shù)據(jù)量的情況下就出現(xiàn)了很多不穩(wěn)定的問(wèn)題,所以需要重點(diǎn)考慮大數(shù)據(jù)量的處理能力和存儲(chǔ)引擎的穩(wěn)定性,一定要經(jīng)過(guò)全面的技術(shù)調(diào)研才能進(jìn)行生產(chǎn)的實(shí)踐
(3)其次就是需要考慮圖數(shù)據(jù)相關(guān)的算法支撐能力,除了基本的相鄰邊查詢能力,是否有比較豐富的圖算法支持,比如在反欺詐場(chǎng)景使用到的是社群發(fā)現(xiàn)算法
(4)最后需要通過(guò)API的方式提供圖數(shù)據(jù)服務(wù),反欺詐應(yīng)用場(chǎng)景提供圖數(shù)據(jù)特征的服務(wù)外,還可以賦能給營(yíng)銷推薦場(chǎng)景
經(jīng)過(guò)多方位的選型調(diào)研,最終選擇了Nebula?Graph作為圖數(shù)據(jù)庫(kù),它采用的是shard-nothing的分布式存儲(chǔ),能夠支持萬(wàn)億級(jí)別的一個(gè)大規(guī)模的機(jī)型的圖的計(jì)算。NebulaGraph的相關(guān)信息可以從他們的官網(wǎng)了解,這里就不贅述了。
4、反欺詐圖特征提取
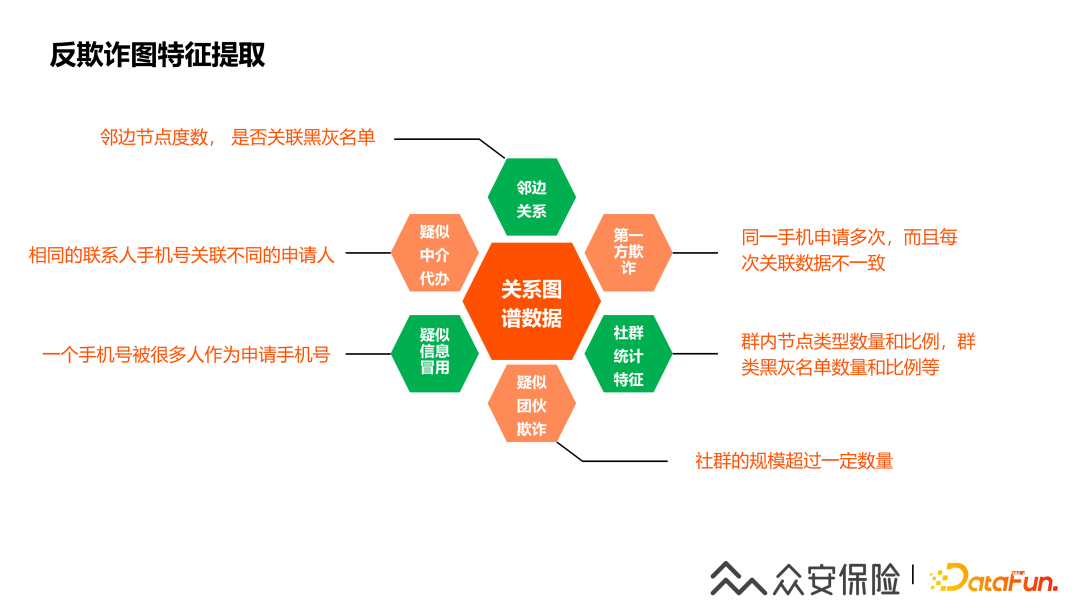
通過(guò)模型團(tuán)隊(duì)對(duì)用戶關(guān)系圖譜的數(shù)據(jù)挖掘,從用戶社群的年齡分布,消費(fèi)預(yù)估水平分布等多維度統(tǒng)計(jì)數(shù)據(jù)出發(fā),我們提取出了一些圖特征,這邊列舉了一批以供大家參考:
(1)第一方欺詐:通過(guò)圖認(rèn)為同一個(gè)人申請(qǐng)多次,而且每次提交的聯(lián)系人等關(guān)聯(lián)信息都不太一致,可以認(rèn)為它是有第一方欺詐的嫌疑。
(2)疑似中介代辦:有部分人的申請(qǐng)人都關(guān)聯(lián)到了相同一個(gè)聯(lián)系人的手機(jī)號(hào)。
(3)疑似信息冒用:就是一個(gè)人的手機(jī)號(hào)可能被很多人使用,可能它出現(xiàn)了信息的泄露。
(4)疑似團(tuán)伙欺詐:看關(guān)系圖譜社群節(jié)點(diǎn)的規(guī)模數(shù)量是否超過(guò)了一定的規(guī)模。
反欺詐策略規(guī)則。通過(guò)一兩個(gè)特征可能沒(méi)辦法精確地對(duì)反欺詐行為進(jìn)行定位,需要來(lái)組合多類的特征,形成反欺詐策略規(guī)則,從而在多方面提升對(duì)用戶反欺詐識(shí)別的準(zhǔn)確度。
五、問(wèn)答環(huán)節(jié)
Q1:Flink的源數(shù)據(jù)由Kafka輸入,那平臺(tái)是否能實(shí)現(xiàn)多條Kafka消息之間的關(guān)聯(lián)查詢?
A1:整個(gè)實(shí)時(shí)業(yè)務(wù)的采集我們是使用Flink完成明細(xì)數(shù)據(jù)的清洗,把DWD層的數(shù)據(jù)回流到TableStore,然后通過(guò)實(shí)時(shí)特征計(jì)算引擎來(lái)實(shí)現(xiàn)數(shù)據(jù)的關(guān)聯(lián),設(shè)置多個(gè)計(jì)算因子,然后通過(guò)這種方式把多條數(shù)據(jù)進(jìn)行關(guān)聯(lián),支持最終特征的產(chǎn)生。比較少在Flink里面進(jìn)行這個(gè)數(shù)據(jù)的關(guān)聯(lián)Join查詢,也就是現(xiàn)在比較流行的ELT的模式。
Q2:特征實(shí)時(shí)計(jì)算方案,貴公司選擇方案2,在變量很多的情況下,怎么保證接口響應(yīng)的效率?
A2:特征計(jì)算是基于特征組維度,一個(gè)特征組下面可能會(huì)有幾十上百個(gè)特征,我們的現(xiàn)在的這個(gè)計(jì)算框架主要性能的消耗是在對(duì)于特征原始數(shù)據(jù)的查詢,只要把原始數(shù)據(jù)查詢出來(lái),特征口徑計(jì)算都是在內(nèi)存里面完成。那么就需要有底層高性能的查詢引擎來(lái)支持,我們現(xiàn)在依賴于阿里云的TableStore查詢引擎來(lái)實(shí)現(xiàn)快速的數(shù)據(jù)查詢能力。
Q3:請(qǐng)教一下,使用無(wú)監(jiān)督的異常檢測(cè)算法,比如孤立森林或者LOFO,應(yīng)該怎么處理APP埋點(diǎn)行為數(shù)據(jù),怎樣提取特征會(huì)比較有效果?
A3:對(duì)于模型的算法不是我所在行的,我的理解是可以從特征質(zhì)量和特征算法指標(biāo)入手,但是沒(méi)有通用的一個(gè)解決方案,要根據(jù)實(shí)際的業(yè)務(wù)數(shù)據(jù)進(jìn)行算法的驗(yàn)證和調(diào)優(yōu),才能夠得到答案。
Q4:關(guān)系圖譜的社區(qū)發(fā)現(xiàn)算法有什么有效的效果評(píng)價(jià)方法嗎?然后這邊一般采用的社區(qū)發(fā)現(xiàn)算法是哪種?
A4:現(xiàn)在采用的是聯(lián)通分量算法。我們關(guān)系圖譜不只是在反欺詐特征計(jì)算使用,也給反欺詐團(tuán)隊(duì)來(lái)做反欺詐調(diào)查使用,他們會(huì)根據(jù)有欺詐嫌疑的用戶,對(duì)我們的關(guān)系圖譜進(jìn)行反向的驗(yàn)證,通過(guò)實(shí)際的調(diào)研來(lái)看算法的效果。
我們是使用SparkGraphx的連通分類算法,通過(guò)找到子圖頂點(diǎn)ID,連通分量算法計(jì)算每個(gè)子圖中的每個(gè)頂點(diǎn)所連接的最小頂點(diǎn)值,然后使用同一個(gè)頂點(diǎn)ID的下所有的節(jié)點(diǎn)ID組合生成一個(gè)新的ID作為社群ID。
Q5:貴司大量依賴圖性能實(shí)時(shí)計(jì)算反欺詐變量,那目前性能存在瓶頸嗎?
A5:主要取決于圖社群的圖關(guān)系數(shù)據(jù)量,如果是查詢普通的用戶,整個(gè)用戶的節(jié)點(diǎn)不會(huì)有太多,基本上會(huì)在十個(gè)節(jié)點(diǎn)以內(nèi)。但是如果這個(gè)人確實(shí)是中介或者說(shuō)有反欺詐嫌疑的用戶,那他的子圖會(huì)非常大,確實(shí)會(huì)出現(xiàn)查詢上的性能超時(shí)的情況。應(yīng)用到反欺詐場(chǎng)景,我們會(huì)設(shè)置兜底方案,比如說(shuō)反欺詐的圖特征接口響應(yīng)超過(guò)了100毫秒,我們就會(huì)默認(rèn)讓這個(gè)用戶通過(guò),盡量不要去影響用戶實(shí)時(shí)的業(yè)務(wù)體驗(yàn)。
Q6:反欺詐的特征跟指標(biāo)的區(qū)別是什么?
A6:反欺詐的特征更關(guān)注用戶的行為特征,更偏向于對(duì)用戶行為的挖掘。
Q7:數(shù)據(jù)量級(jí)是多少?實(shí)時(shí)特征任務(wù)的執(zhí)行時(shí)長(zhǎng)大概是多少?離線計(jì)算任務(wù)的時(shí)長(zhǎng)是多少?可以介紹一下嗎?
A7:現(xiàn)在我們每天特征的查詢量會(huì)在八九千萬(wàn)的級(jí)別。實(shí)時(shí)特征的實(shí)時(shí)任務(wù)時(shí)長(zhǎng),依賴于Flink的實(shí)時(shí)能力,在幾十毫秒之內(nèi)就可以完成這個(gè)數(shù)據(jù)的同步。我們的特征查詢依賴于阿里云TableStore的能力,每次的特征查詢也都在100毫秒左右,所以性能還是比較有保障的。
Q8:Flink計(jì)算完成后,實(shí)時(shí)特征查詢可能缺失嗎?
A8:是有可能缺失的。因?yàn)楝F(xiàn)在是監(jiān)聽(tīng)Binlog的方式實(shí)時(shí)寫入的,如果在業(yè)務(wù)高峰期,特別是在有些跑批業(yè)務(wù)場(chǎng)景的這個(gè)情況下,可能Binlog的數(shù)據(jù)量非常大,那我們整個(gè)實(shí)時(shí)數(shù)據(jù)的采集耗時(shí)可能比平時(shí)要更長(zhǎng)。比如說(shuō)這個(gè)用戶在授信過(guò)程后馬上進(jìn)行支用的話,他的一些授信的數(shù)據(jù)還沒(méi)有完全及時(shí)地寫到在線查詢引擎,可能這一次的實(shí)時(shí)查詢就會(huì)有缺失的情況。
Q9:特征計(jì)時(shí)計(jì)算場(chǎng)景下長(zhǎng)窗口特征進(jìn)行計(jì)算時(shí)會(huì)不會(huì)存在效率問(wèn)題,然后是如何解決的?
A9:我們現(xiàn)在的存儲(chǔ)其實(shí)還是基于用戶維度的存儲(chǔ)方式,主鍵是用戶的userID,那我們會(huì)通過(guò)tablestore的range查詢的方式,把用戶相關(guān)的所有數(shù)據(jù)都查詢出來(lái)。
其實(shí)在金融場(chǎng)景,不像電商或者內(nèi)容查詢的業(yè)務(wù)場(chǎng)景,一個(gè)用戶的交易數(shù)據(jù)、業(yè)務(wù)數(shù)據(jù)并不太多,其實(shí)不會(huì)存在有太大的效率問(wèn)題。
Q10:特征的維度如何界定?會(huì)有一些少見(jiàn)的數(shù)據(jù)作為維度嗎?比如優(yōu)惠券ID等。
A10:優(yōu)惠券ID等可能在營(yíng)銷場(chǎng)景有不同的維度和特征。在風(fēng)控業(yè)務(wù)場(chǎng)景,特征維度基本上基于人維度的,比如用戶身份證、手機(jī)號(hào),還有用戶這個(gè)組件的維度,比較少見(jiàn)基于這種優(yōu)惠券ID維度的特征。
Q11:有深度網(wǎng)絡(luò)方面的特征提取嗎?
A11:現(xiàn)在還沒(méi)有這方面的探索。
Q12:在實(shí)際應(yīng)用中,F(xiàn)link最大的計(jì)算時(shí)間窗口有多大,是否超過(guò)48小時(shí)?
A12:這個(gè)會(huì)有超過(guò)的,最大窗口的范圍會(huì)在三天。但是實(shí)時(shí)特征場(chǎng)景,窗口基本上不會(huì)太大,一般是分鐘級(jí)別。對(duì)實(shí)時(shí)性要求不高的一些特征場(chǎng)景,我們可以支持在3天的窗口。這個(gè)比較耗費(fèi)資源,這種情況會(huì)比較少。
Q13:請(qǐng)問(wèn)目前上線的實(shí)時(shí)模型占比多嗎?然后遇到過(guò)什么問(wèn)題嗎?
A13:如果相對(duì)于整個(gè)特征體系來(lái)說(shuō)的話,是不多的。但是我們的模型覆蓋了整個(gè)金融業(yè)務(wù)領(lǐng)域,營(yíng)銷場(chǎng)景其實(shí)也有,具體數(shù)量可能不太好透露。
現(xiàn)在我們遇到的問(wèn)題主要是特征的開(kāi)發(fā)衍生和實(shí)際的線上化的特征應(yīng)用是由兩個(gè)團(tuán)隊(duì)去開(kāi)發(fā),之間的實(shí)現(xiàn)會(huì)有些不一致的情況。在模型開(kāi)發(fā)的時(shí)候,它依賴的是離線的特征挖掘。那在生產(chǎn)時(shí)候我們是用實(shí)時(shí)特征的來(lái)去作為模型的入?yún)⒆兞浚瑪?shù)據(jù)會(huì)有所差異,對(duì)于模型的PSI穩(wěn)定性就會(huì)有一些影響。
Q14:線上線下的一致性如何解決?
A14:這是個(gè)非常大的話題,現(xiàn)在比較流行的流批一體化的方案也是在嘗試解決這個(gè)問(wèn)題。從我的理解來(lái)說(shuō),首先lambda架構(gòu)可能要做一些調(diào)整,通過(guò)數(shù)據(jù)湖的方式來(lái)實(shí)現(xiàn)離線實(shí)時(shí)的同一份存儲(chǔ)。引擎方面要統(tǒng)一和存儲(chǔ)方面要統(tǒng)一,當(dāng)然這個(gè)成本會(huì)比較大。最后就是特征口徑的開(kāi)發(fā),在特征挖掘開(kāi)發(fā)的時(shí)候的口徑直接應(yīng)用到生產(chǎn)中,具于統(tǒng)一的口徑進(jìn)行生成應(yīng)用,那這樣才能達(dá)到和之前特征開(kāi)發(fā)口徑一致。
Q15:實(shí)時(shí)特征如果獲取不到或者返回很慢,線上模型或者決策引擎怎么處理?
A15:這個(gè)是會(huì)經(jīng)常碰到的一些問(wèn)題。比如說(shuō)模型和決策引擎依賴特征是三方的特征,那在三方不可用的情況下,我們需要去怎么處理。這種情況要看我們對(duì)這個(gè)特征的依賴情況,如果是強(qiáng)依賴,那我們可能等待這個(gè)實(shí)時(shí)特征能夠成功獲取,然后再跑真正的模型和策略。如果是弱依賴,那在模型的開(kāi)發(fā)的時(shí)候,就會(huì)考慮這種情況,會(huì)用其他的特征或者其他的方式進(jìn)行處理。那決策引擎同樣也是如此,可以定制不同的決策規(guī)則來(lái)規(guī)避這種情況。